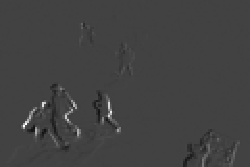Standard OR-PCA decomposes streaming data into low-rank + sparse components, but its performance heavily depends on tuning two explicit regularization parameters — dataset-sensitive and impractical for real-world streaming.
OR-PCA factorizes \(\mathbf{X} = \mathbf{L}\mathbf{R}^\top\) and alternates between estimating the sparse outlier \(\mathbf{e}_t\), the coefficient \(\mathbf{r}_t\), and the subspace basis \(\mathbf{L}\). Each involves an explicit regularizer (\(\lambda_1\) or \(\lambda_2\)) that must be tuned via grid search or cross-validation — methods that are computationally expensive and often fail to generalize to unseen data.
Early-stopped momentum gradient descent. The stopping time \(T_r\) is the implicit ridge parameter (\(\lambda = 2/t^2\)), replacing \(\lambda_1\) in the coefficient update.
A new reparameterization \(\mathbf{L} = \mathbf{g}^{\odot 2}\mathbf{1}_r \odot \mathbf{V}\) separates row magnitude from direction, implicitly controlling \(\|\mathbf{L}\|_F^2\) without \(\lambda_1\).
for t = 1 to n do
Reveal z_t
repeat
r_t ← MGD(z_t - e_t, T_r) // implicit l2
e_t ← HPGrad(z_t - L·r_t, T_e) // implicit l1until convergence
L ← HPGroupGrad(z_t - e_t, r_t, T_L, L) // implicit Frobeniusend forreturn L, R, E
IV. Results — Synthetic
Expressed Variance & ablation
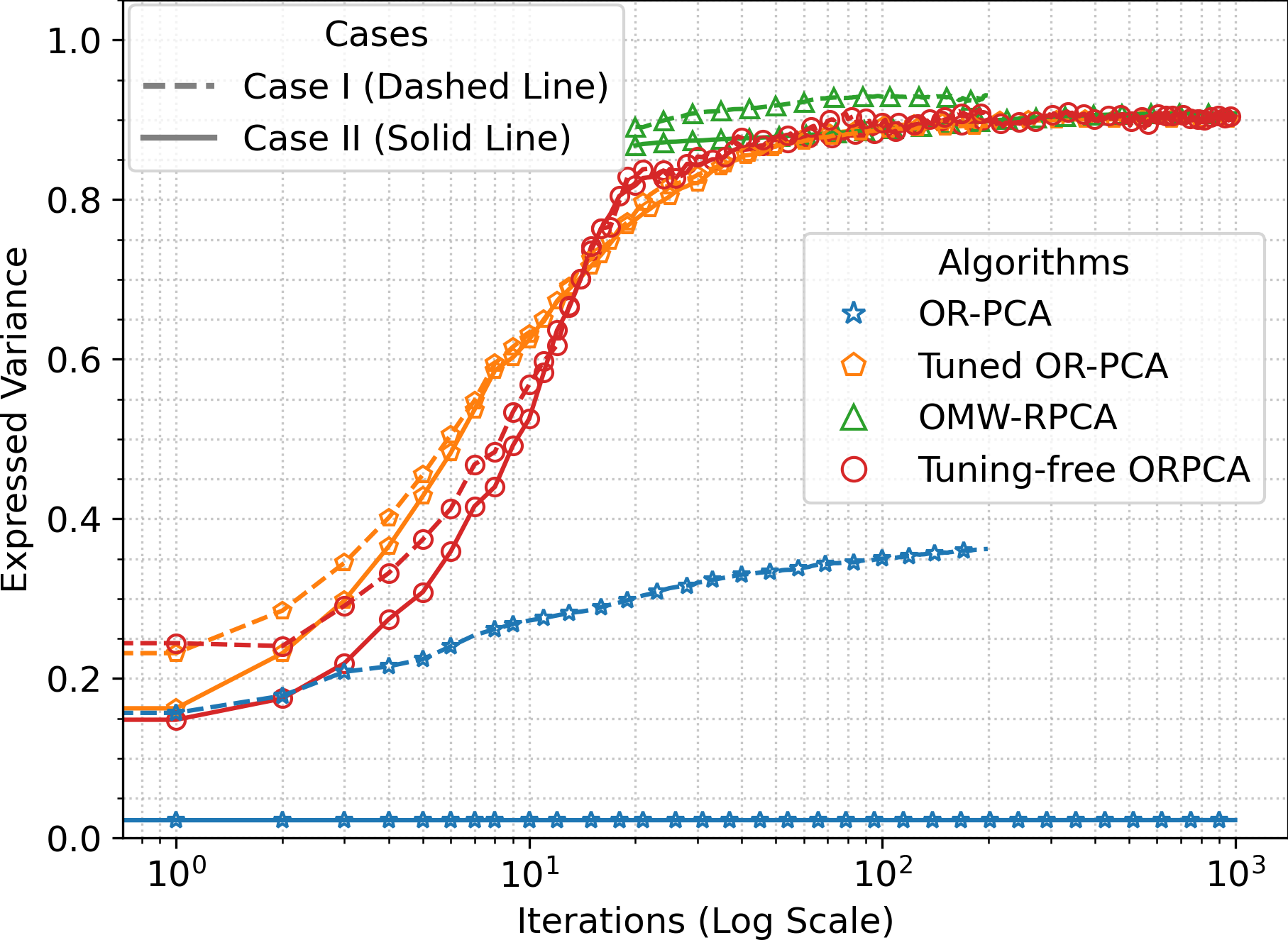
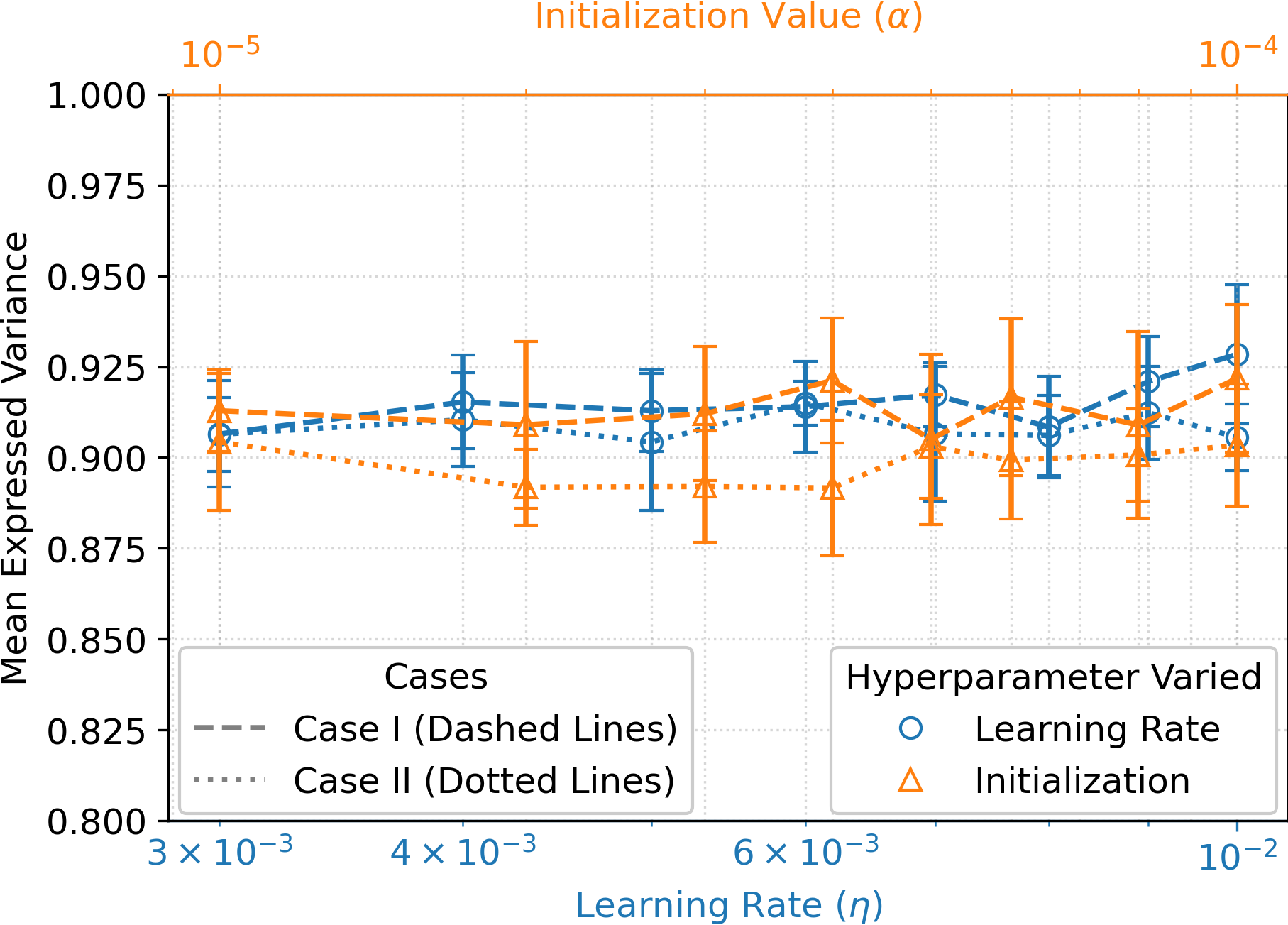
TF-ORPCA matches carefully tuned baselines without any tuning; performance is stable across wide ranges of \(\eta\) and \(\alpha\).
Place EV_Comparison_Combined.png in FiguresFile/
Fig 1. EV vs. number of samples. TF-ORPCA consistently outperforms default OR-PCA (EV ≤ 0.4).
Place Combined_Ablation_Plot.png in FiguresFile/
Fig 2. Ablation — EV is stable across learning rate and initialization ranges.
V. Results — Video Surveillance
Background / foreground separation
Same hyperparameters for all three datasets. Frames loop at 10 fps, matching the paper’s animated results.
Bungalows — Dynamic lighting
Input \(\mathbf{z}_t\)
Ours — Background \(\mathbf{L}\)
Ours — Foreground \(\mathbf{E}\)
Frame 2 / 40
PETS2006 — Surveillance
Input \(\mathbf{z}_t\)
Ours — Background \(\mathbf{L}\)
Ours — Foreground \(\mathbf{E}\)
Frame 2 / 40
Pedestrians — Outdoor
Input \(\mathbf{z}_t\)
Ours — Background \(\mathbf{L}\)
Ours — Foreground \(\mathbf{E}\)
Frame 2 / 40
VI. Takeaway
Three implicit regularizers, zero tuning
TF-ORPCA employs three problem-specific implicit regularization techniques — a modified gradient descent for implicit \(\ell_1\), an early-stopped MGD for implicit \(\ell_2\), and a novel reparameterization for implicit Frobenius norm control. Unlike traditional OR-PCA, the algorithm is insensitive to its own hyperparameters and does not require extensive tuning. It clearly extracts foreground and background components without the artifacts — shadowing, gray patches — often seen with traditional approaches.